Autothrottle: Manage Resources for SLO-Targeted Microservices
1 minutes read (267 words)
August 17th, 2023
In this is post we will walk through the research paper Autothrottle: A Practical Bi-Level Approach to Resource Management for SLO-Targeted Microservices.
Autothrottle: A Practical Bi-Level Approach to Resource Management for SLO-Targeted Microservices
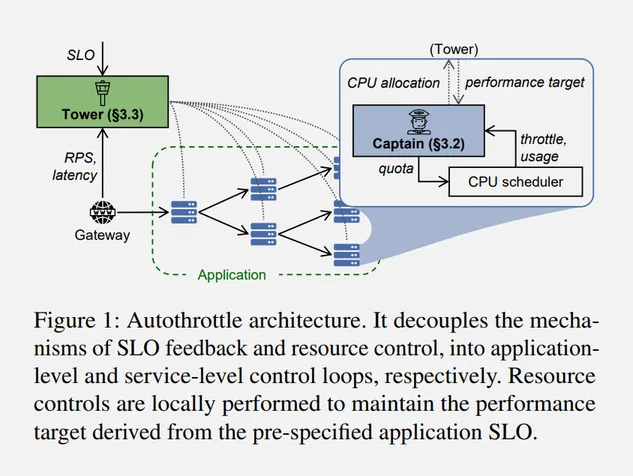
We propose Autothrottle as a bi-level learning-assisted framework. It consists of (1) an application-level lightweight controller that learns to “assist” local heuristic resource control, with the visibility of application workloads, latencies, and the SLO; and (2) per-microservice agile controllers that continuously perform fine-grained CPU scaling, using local metrics and periodic “assistance” from the global level.
Microservices have become a popular architecture paradigm, providing benefits like independent scaling and modularity. However, operating and maintaining microservices introduces challenges around efficiently managing resources to provide good user experience within cost constraints.
This paper presents an intriguing bi-level control approach called Autothrottle that decouples application-level SLO monitoring from service-level resource controllers. The notion of a CPU throttle-based performance target is quite exciting, as it provides a way to bridge these levels. Platform engineers may find several practical takeaways from this paper when managing microservices.
Practical Takeaways for Practitioners
- The bi-level structure aligns well with aggregating metrics at the application level while collecting per-service metrics. This incremental observability is useful.
- Tracking CPU throttling events can help set alerts and monitor service health. Throttling often indicates problems.
- The online learning algorithm for autoscaling is handy for capacity planning using production traffic data.
- The rapid feedback control and rollback mechanisms inform techniques for incident response.
- Load testing microservices while correlating with metrics helps test observability.
- The techniques could extend beyond CPU to memory, IO, network for holistic resource management.
- The modular design enables gains without full end-to-end traces. Failures in one service are mitigated by others.
- Integration with Kubernetes operators would be valuable for microservice deployments.
Summary
The paper presents a practical bi-level resource management approach for microservices. The key takeaway for platform engineers is the value of incremental observability wins from decoupled monitoring and control. Tracking emerging proxy metrics like CPU throttling provides alerts for potential problems. And online learning algorithms lend themselves to continuous improvement of autoscaling policies.